안녕하세요! 오늘은 흥미로운 논문을 소개해드릴 거예요. 움직이는 무선 센서를 이용해 수로를 똑똑하게 감시하는 시스템에 관한 내용입니다. 여러분이 예상하신 것보다 더 복잡하고 멋진 기술이 담겨 있으니 차근차근 따라와주세요!
📋 논문 정보
먼저 논문의 기본 정보를 정리해드릴게요.
- 제목: Movable Wireless Sensor-Enabled Waterway Surveillance with Enhanced Coverage Using Multi-Layer Perceptron and Reinforced Learning
- 한글 제목: 움직임이 가능한 무선 센서를 이용한 수로 감시 시스템: MLP와 강화학습 기반 커버리지 최적화
- 저자: Minsoo Kim, Hyunbum Kim (인천대학교 임베디드시스템공학과)
- 발행: Electronics, Volume 14, Issue 16, Article 3295 (2025년 8월)
- DOI: https://doi.org/10.3390/electronics14163295
이 논문은 Creative Commons Attribution (CC BY) 4.0 라이선스로 공개되어 있어요. 누구나 자유롭게 접근하고 활용할 수 있습니다.
🎯 왜 이 논문이 중요한가?
수로(Waterway)는 무엇인가요?
수로라고 하면 생소할 수 있지만, 우리 주변의 강, 하천, 항구, 운하 같은 모든 수상 환경을 의미해요. 이런 공간들은 단순히 물이 있는 곳이 아니라 다음과 같은 복잡한 특성을 가지고 있습니다:
- 🚢 선박의 이동: 시시각각 변하는 선박의 경로와 위치
- 🌊 수질 변화: 시간과 계절에 따라 달라지는 수질 상태
- 🐠 생태계 영향: 수생 생물과 생태 환경
기존 센서 시스템의 문제점
기존의 정적(고정된) 센서 네트워크는 이런 동적인 수로 환경에서 큰 문제를 가지고 있었어요:
| 문제점 | 설명 |
|---|---|
| 고정된 위치 | 센서가 고정되어 있어 움직이는 선박을 제대로 추적 불가능 |
| 불균형한 커버리지 | 일부 영역은 과도하게 감시하고 다른 영역은 놓칠 수 있음 |
| 오래된 정보(AoI) | 센서가 움직이지 않으면 데이터가 점점 낡아짐 |
이 논문에서 제시하는 움직이는 센서는 이런 문제들을 한 번에 해결할 수 있어요!
🔧 어떻게 작동하는가?
두 단계의 영리한 전략
이 시스템은 정말 똑똑하게 설계되었어요. 센서가 하는 일을 두 가지 단계로 나누었거든요:
📍 초기 위치 (랜덤하게 배치)
↓
┌────────────────────────┐
│ 🎯 1단계: 이동 단계 │ → MLP를 이용해 목표 영역으로
빠르게 이동
│ (Movement Phase) │ • 입력: 현재 위치 (x, y)
│ │ • 출력: 어느 방향으로 움직
일지 결정
└────────────────────────┘
↓
┌────────────────────────┐
│ 🎯 2단계: 배치 단계 │ → RL을 이용해 최적으로 배열
│ (Deployment Phase) │ • 입력: 센서들의 위치
│ │ • 출력: 최적화된 위치 조정
└────────────────────────┘
↓
✅ 최종 센서 배치 완료!
이렇게 두 가지로 나누면:
- 1단계는 빠르고 간단한 계산으로 목표에 빨리 도달
- 2단계는 복잡한 최적화로 최고의 배치를 찾을 수 있어요
🧠 첫 번째 무기: MLP(다층 퍼셉트론)
MLP가 뭐하는 거예요?
MLP는 가장 간단한 인공신경망이에요. 여러분도 어릴 때 본 그 신경망 다이어그램의 기본형이죠! 입력에서 출력까지 일직선으로 연결된 구조예요.
MLP의 작동 원리
이 시스템에서 MLP는 정말 단순하지만 강력한 일을 해요:
입력층 (센서의 현재 위치 x, y)
↓
은닉층 1 ← ReLU 활성화
↓
은닉층 2 ← ReLU 활성화
↓
은닉층 3 ← ReLU 활성화
↓
출력층 ← Softmax로 정규화
↓
확률값 (상으로 갈 확률 30%, 하로 갈 확률 20%, ... )
쉽게 말하면:
- 센서가 **”지금 어디 있어?”**라고 물으면
- MLP가 **”그럼 이 방향으로 가!”**라고 답해주는 거예요
왜 MLP를 선택했을까?
정말 중요한 부분인데, MLP를 선택한 이유는:
⚡ 매우 빠름: 훈련 후 딱 O(1) 상수 시간이면 답을 냄
- 환경이 얼마나 크든지 상관없어요!
- 무거운 그래프 알고리즘은 O(n log n) 시간이 필요하지만, MLP는 항상 같은 시간
💡 간단하고 명확함: 복잡한 구조 없이도 충분히 효과적
🚀 실시간 적용 가능: 센서가 매번 빠르게 판단할 수 있음
수학으로 보는 MLP 훈련
MLP를 훈련시킬 때는 두 가지 손실 함수를 결합해요:
첫 번째: 분류 손실 (Classification Loss)
L_classification = -Σ(y_i · log(ŷ_i))
💬 “센서가 예측한 방향이 정답 방향과 맞나?”를 측정해요
두 번째: 거리 손실 (Distance-Based Loss)
L_distance =
- 0 (목표까지의 거리가 줄어들면)
- (거리 감소분)² (목표까지의 거리가 안 줄어들면)
💬 “센서가 실제로 목표에 가까워지고 있나?”를 측정해요
최종 훈련 손실:
L_total = α · L_classification + β · L_distance
두 목표를 균형있게 동시에 달성하도록 훈련시킨다는 뜻이에요!
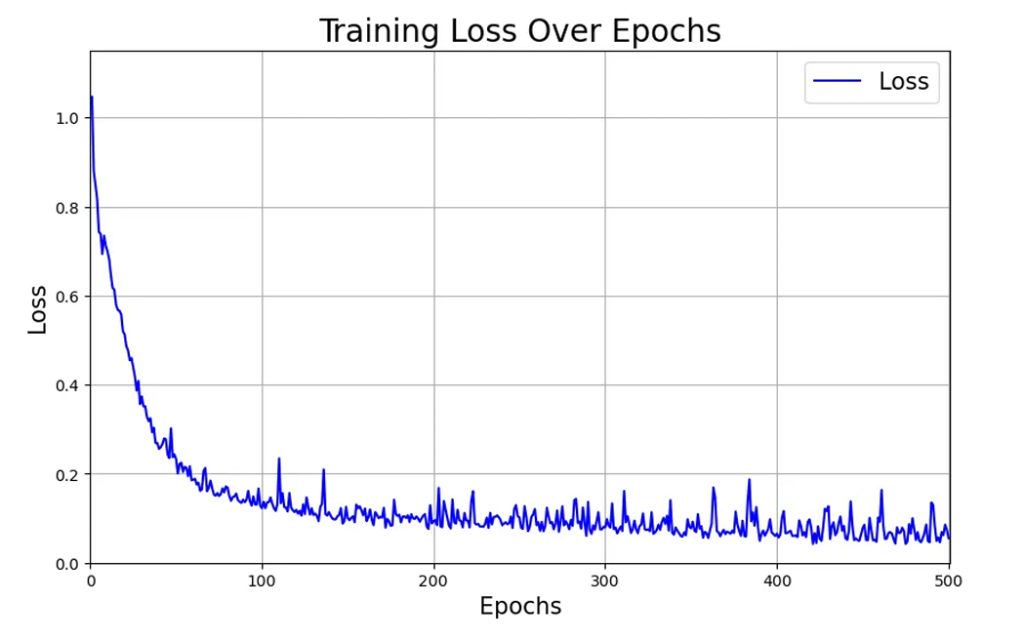
실험 결과: 정말 작동하나요?
훈련 조건:
- 훈련 데이터: 100~500개 경로
- 반복 학습: 100~500번
- 학습률: 0.001
결과 정리:
| 데이터 개수 | 200 에포크 | 300 에포크 | 500 에포크 |
|---|---|---|---|
| 100개 | 약 70% | 약 75% | 약 80% |
| 300개 | 약 88% | 약 92% | 약 95% |
| 500개 | 약 95% | 약 97% | 약 100% |
보세요! 충분한 데이터와 학습으로 거의 100%에 가까운 성공률을 달성했어요! 🎉
💪 두 번째 무기: 강화학습(RL)
강화학습이 뭐하는 거예요?
만약 MLP가 “A지점에서 B지점으로 어떻게 가지?”를 해결한다면, 강화학습은 “여러 센서들을 어떻게 배열할까?”라는 훨씬 더 복잡한 문제를 해결해요.
강화학습은 정말 재미있는 아이디어예요. 마치:
- 아이가 처음 자전거를 타며 배우는 것처럼
- 에이전트가 시행착오를 통해 최고의 전략을 배우는 거예요
강화학습의 핵심 요소
강화학습 시스템을 이해하려면 3가지만 알면 돼요:
1️⃣ 상태(State)
현재 상황:
- 각 센서가 어디에 있는가?
- 현재까지 커버된 영역은 어디인가?
2️⃣ 행동(Action)
할 수 있는 일:
- 각 센서를 조금씩 움직이기
- 목표 영역 내에만 머물기
3️⃣ 보상(Reward)
점수 계산:
- 많은 영역을 커버하면 +점수 ✅
- 센서들이 겹치면 -점수 ❌
- 경계를 벗어나면 -점수 ❌
보상 함수 상세 설명
이 논문에서 가장 똑똑한 부분이 바로 보상 함수예요. 여러 목표를 동시에 달성해야 하니까요!
Reward = 커버리지 - (중복 페널티 + 경계 페널티)
커버리지 (Coverage):
Coverage = Σ(감시되는 모든 영역의 합)
✅ 이것은 최대화하고 싶은 것: 최대한 많은 영역을 감시
중복 페널티 (Overlap Penalty):
OverlapPenalty = Σ(센서 간 겹치는 영역들)
❌ 이것은 최소화하고 싶은 것: 같은 곳을 여러 번 감시하는 건 낭비
경계 페널티 (Boundary Penalty):
BoundaryPenalty = Σ(경계 밖에 있는 센서들의 위반도)
❌ 이것도 최소화하고 싶은 것: 모든 센서가 목표 영역 안에 있어야 함
PPO 알고리즘: 안정적인 학습
강화학습도 여러 종류가 있는데, 이 논문에서 사용한 것은 **PPO(Proximal Policy Optimization)**이에요. 왜 PPO를 선택했을까요?
- 🎯 안정적: 학습 과정이 요동치지 않음
- ⚖️ 균형잡힘: 모험(탐색)과 기존 지식(활용)의 균형을 잘 맞춤
- 🏆 효과적: 복잡한 최적화 문제도 잘 풀어냄
PPO는 두 개의 신경망을 함께 사용해요:
┌──────────────────────┐
│ 정책 네트워크 │ ← "이렇게 하는 게 맞나?"
│ │
│ 입력: 센서 위치들 │
│ 출력: 어떻게 움직일지 │
└──────────────────────┘
┌──────────────────────┐
│ 가치 네트워크 │ ← "지금 상황이 좋은가?"
│ │
│ 입력: 센서 위치들 │
│ 출력: 현재 상황점수 │
└──────────────────────┘
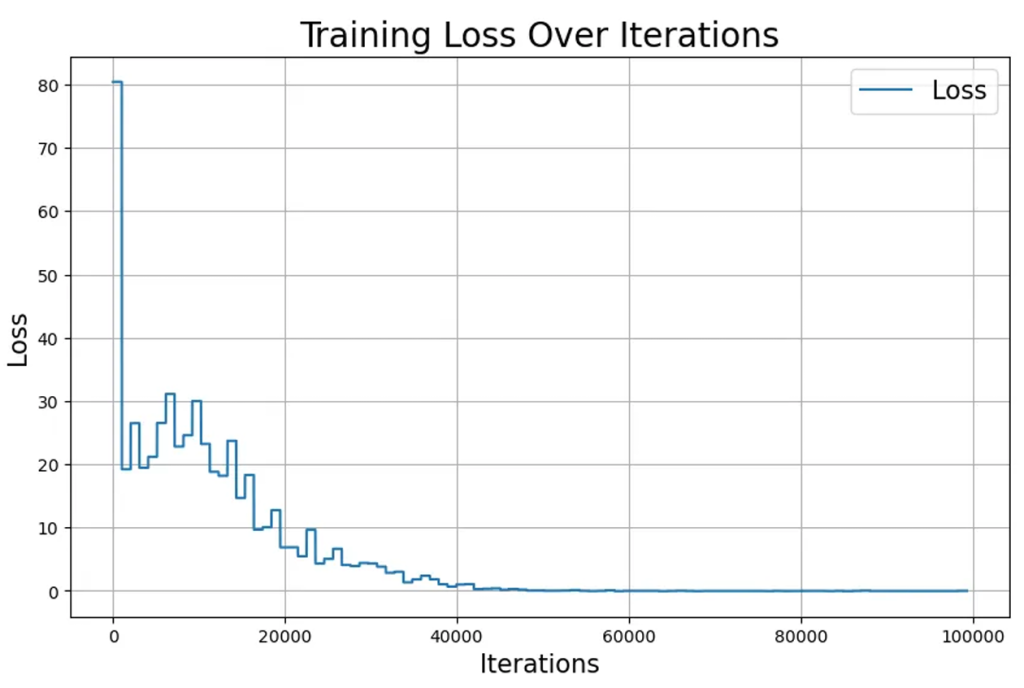
강화학습 실험 결과
훈련 조건:
- 총 훈련 스텝: 100,000번
- 한 번에 처리하는 스텝: 1,024개
- 반복 학습: 100번
- 학습률: 0.0001 (매우 천천히 배움)
결과:
손실값이 처음에는 매우 높았어요 (센서들이 엉망으로 배치됨). 하지만:
- 🔥 초반: 빠르게 개선됨 (명확한 개선 가능)
- 📈 중반: 천천히 개선됨 (세부 최적화)
- ✨ 후반: 안정적으로 수렴 (더 이상 개선 안 됨)
이것은 PPO가 정상적으로 작동한다는 증거예요!
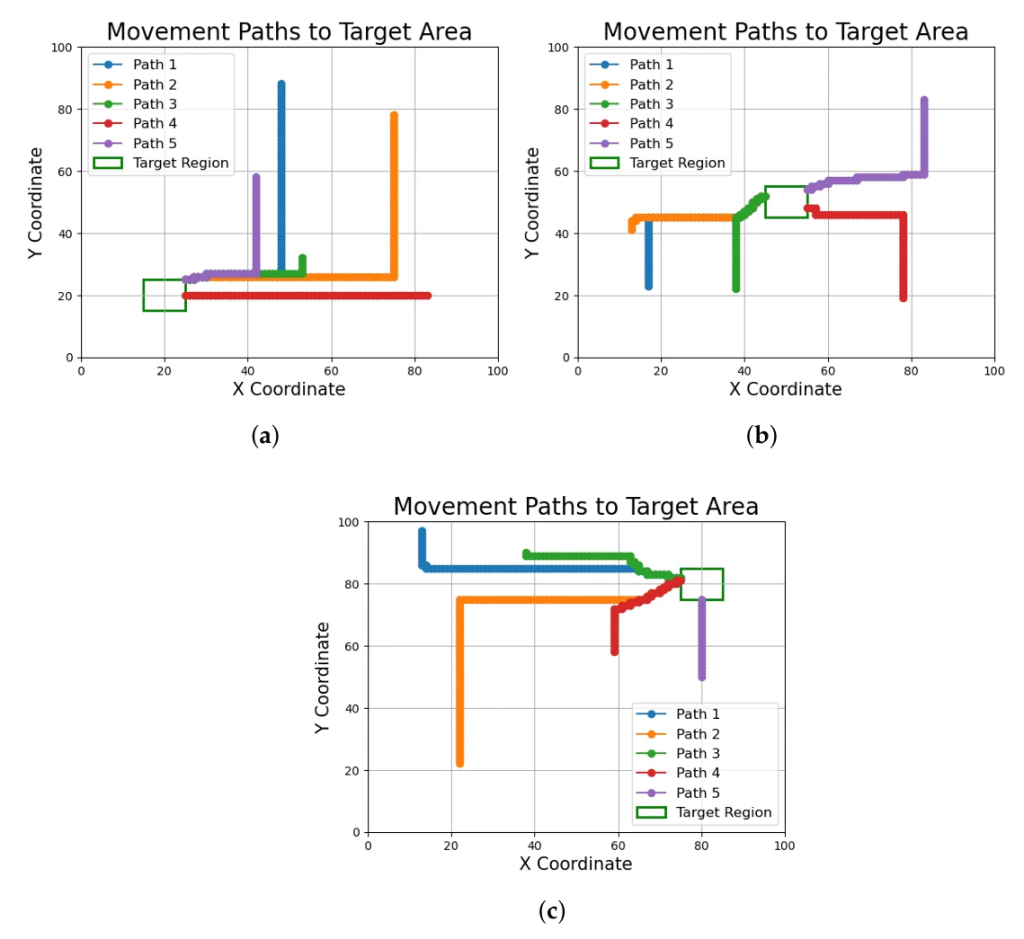
📊 실제 성능 비교
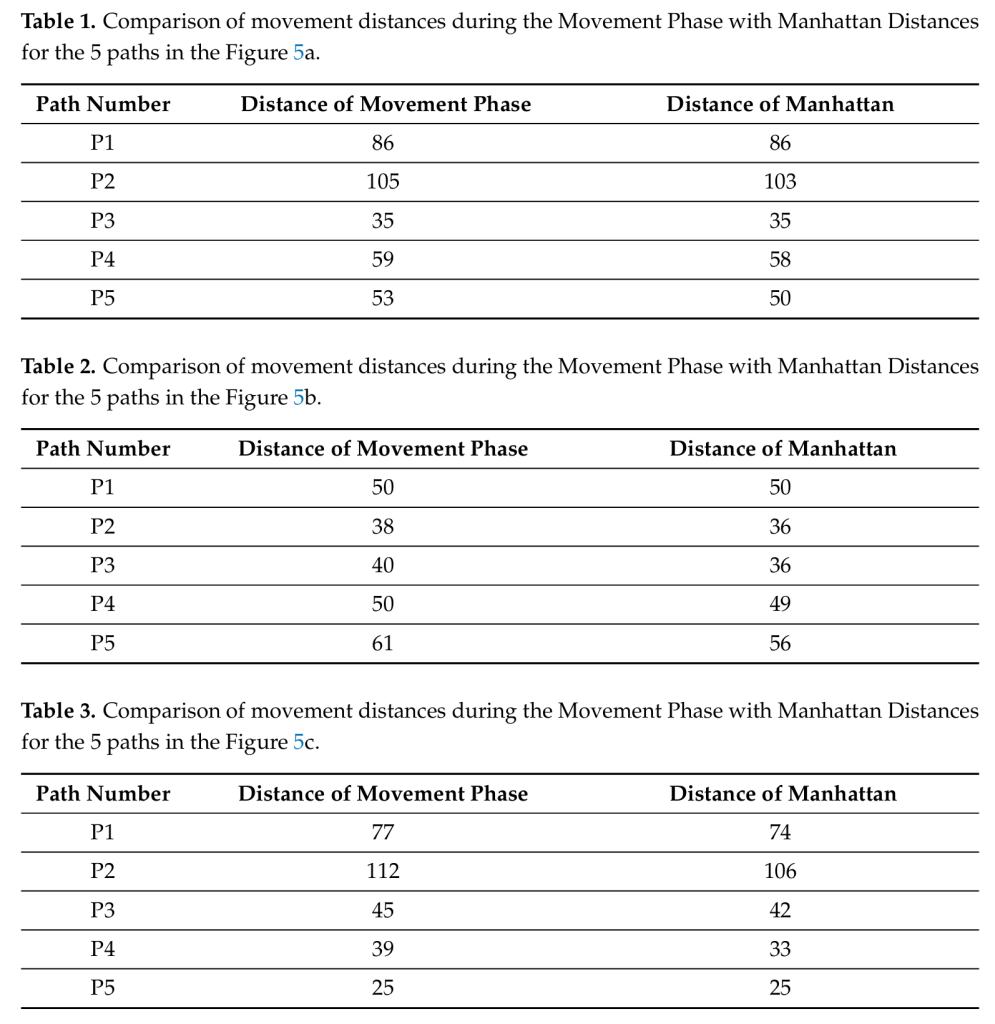
이동 단계: 경로 효율성
연구자들이 MLP로 계산한 경로와 **최단 경로(Manhattan Distance)**를 비교했어요. 결과는?
| 경로 | MLP 이동거리 | 최단거리 | 효율성 |
| 경로1 | 86 | 86 | 100% |
| 경로2 | 105 | 103 | 98% |
| 경로3 | 35 | 35 | 100% |
| 경로4 | 59 | 58 | 99% |
| 경로5 | 53 | 50 | 94% |
| 평균 | – | – | 98.8% |
결론: MLP는 최단 경로의 95~100% 수준의 효율성을 달성했어요!
여기서 정말 중요한 건:
- ⚡ 계산이 O(1): 아무리 큰 환경이든 같은 시간
- 🚀 경로 효율: 최단 경로와 거의 똑같음
- 🎯 실용성: 약 1~5%의 작은 손실로 엄청난 속도 향상
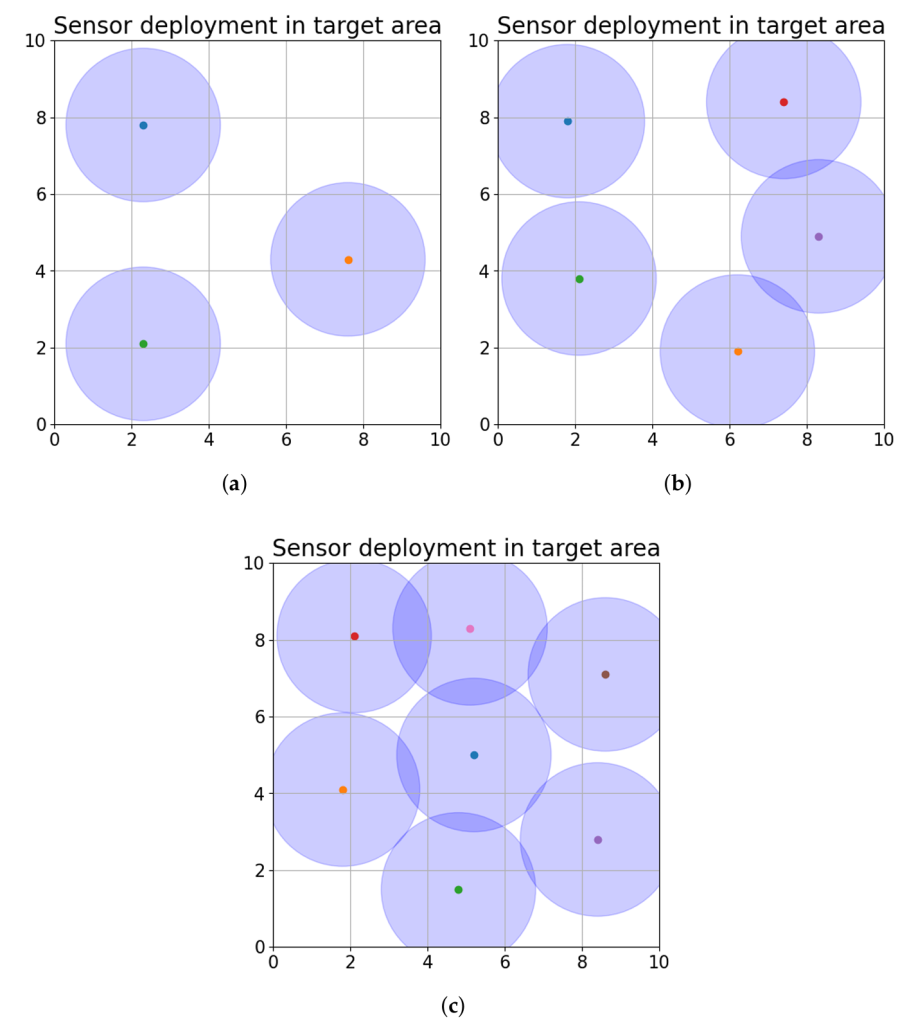
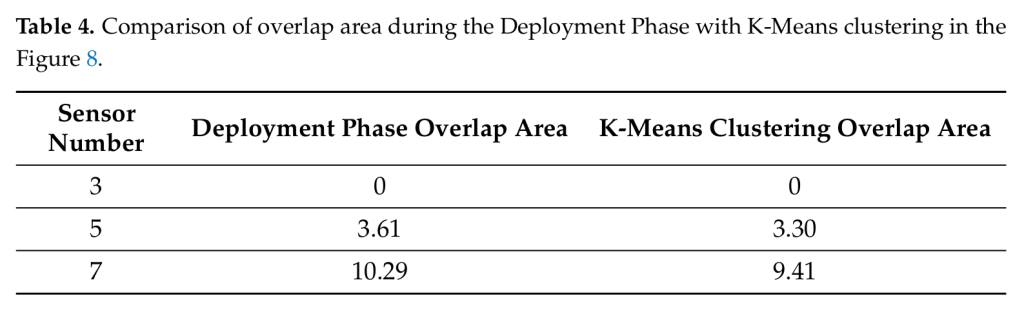
배치 단계: K-Means와의 비교
이제 배치 단계의 결과를 봐요. 기존의 유명한 클러스터링 알고리즘 K-Means와 비교했어요.
중복 면적 비교 (단위: m²):
| 센서 개수 | 제안 알고리즘(RL) | K-Means | 차이 |
|---|---|---|---|
| 3개 | 0 | 0 | 0 |
| 5개 | 3.61 | 3.30 | +9.4% |
| 7개 | 10.29 | 9.41 | +9.3% |
해석:
- 3센서: 둘 다 완벽해요! (0 중복)
- 5센서: RL이 약간 더 많이 겹침 (K-Means이 0.31 m² 더 적음)
- 7센서: 센서 밀도가 높아지면서 불가피한 중복 증가
언뜻 보면 K-Means가 더 좋아 보이나요? 하지만 중요한 차이가 있어요:
| 특성 | 제안(RL) | K-Means |
|---|---|---|
| 커버리지 최대화 | ✅ 명시적으로 함 | ❌ 고려 안 함 |
| 경계 제약 | ✅ 명시적 페널티 | ❌ 기본만 함 |
| 동적 환경 적응 | ✅ 가능 | ❌ 불가능 |
| 제약 통합 | ✅ 우수 | ❌ 제한적 |
결론: K-Means와 비슷한 중복율(약 9% 차이)이지만, 더 똑똑한 최적화를 동시에 달성했어요!
🌟 이 논문의 주요 기여
이동 단계 기여
간단하면서도 효과적인 MLP
- 신경망을 처음 접하는 사람도 이해할 수 있는 구조
- 하지만 실전에서는 충분히 강력함
이중 손실 함수 설계
- 방향 예측 정확도 + 실제 거리 효율성
- 두 가지를 동시에 최적화
상수 시간 복잡도
- O(1)로 환경 크기의 영향 제거
- 실시간 응용에 최적
배치 단계 기여
통합된 보상 함수
- 커버리지 최대화
- 중복 최소화
- 경계 제약 관리
- 세 가지를 동시에!
PPO 기반의 안정적 훈련
- 강화학습의 불안정성 극복
- 실무 적용 가능한 신뢰성
동적 환경 대응
- K-Means 같은 정적 방법과 달리
- 상황이 변하면 다시 배치 가능
실험 평가의 우수성
- ✅ 최소 100회 반복 실험 (통계적 신뢰성)
- ✅ 다양한 조건 변화 (데이터 양, 에포크, 센서 개수)
- ✅ 기존 방법과의 정량적 비교
- ✅ 손실값 수렴 등 상세한 분석
🔮 앞으로 어떻게 개선될까?
논문의 저자들은 이미 다음과 같은 개선 방향을 제시했어요:
1️⃣ AoI(Age of Information) 통합
현재: 👉 공간만 최적화 (어디를 감시하는가) 미래: 👉 시간도 최적화 (정보가 얼마나 최신인가)
빠르게 변하는 수로 환경에서는 오래된 정보는 쓸모가 없어요!
2️⃣ 다양한 센서 특성 고려
현재: 👉 모든 센서가 똑같은 감지 반경 미래: 👉 성능이 다른 센서들을 섞어 사용
비용 최적화와 현실성을 동시에 달성할 수 있어요.
3️⃣ 통신 제약 반영
현재: 👉 센서 위치만 최적화 미래: 👉 센서 간 통신 범위도 고려
센서들이 서로 정보를 나눌 수 있어야 진짜 네트워크니까요!
4️⃣ 현실적인 수로 환경
현재: 👉 2D 격자 기반 시뮬레이션 미래: 👉 실제 수로의 지형, 물의 흐름 등 반영
결국은 실제 강과 하천에 적용해야 하니까요!
💼 실무 적용 시 알아야 할 것들
장점 (사용해야 하는 이유) ✅
⚡ 초고속 추론
- MLP의 O(1) 시간복잡도
- 실시간 의사결정 가능
💰 비용 효율성
- 적은 수의 센서로 높은 커버리지
- 유지비 절감
🔄 적응성
- 동적으로 변하는 환경에 대응
- 새로운 상황에 맞게 재배치 가능
📈 확장성
- 더 많은 센서 추가 가능
- 더 큰 영역으로 확장 가능
한계 (알아두어야 하는 것들) ⚠️
🛣️ 완벽한 경로는 아님
- 최단 경로의 약 95-100%
- 약 5% 정도의 추가 거리 이동
🎯 약간의 중복 증가
- K-Means 대비 약 9% 더 많은 중복
- 충분히 무시할 수 있는 수준이긴 함
⏰ 정보의 신선도 미포함
- 현재는 공간 커버리지만 최적화
- 데이터의 나이를 고려하지 않음
🌍 현실과의 격차
- 2D 격자 환경 가정
- 실제 지형의 복잡성 미반영
🛠️ 기술 스택 정리
사용한 기술
프로그래밍:
- Python 3.8
- PyTorch 2.0 (딥러닝 프레임워크)
신경망 기술:
- ReLU 활성화 함수 (은닉층)
- Softmax 활성화 함수 (확률 정규화)
- 완전 연결층 (Fully Connected Layers)
최적화 알고리즘:
- SGD (확률적 경사 하강법)
- Adam (적응형 학습률)
- PPO (강화학습 알고리즘)
평가 메트릭:
- FindRatio: 목표 도달률(%)
- Coverage Ratio: 감시 영역 비율
- Overlap Ratio: 중복도
- Training Time: 훈련 시간
🎓 핵심 개념들 한눈에
| 용어 | 의미 | 중요성 |
|---|---|---|
| MLP | 다층 퍼셉트론 | 빠르고 간단한 신경망 |
| RL/PPO | 강화학습/최적화 알고리즘 | 복잡한 배치 문제 해결 |
| 커버리지 | 센서가 감시하는 영역 비율 | 시스템 효과성의 핵심 지표 |
| 중복(Overlap) | 여러 센서 감시 범위의 겹침 | 자원 낭비 정도를 나타냄 |
| AoI | 정보의 나이 | 동적 환경에서 중요 |
| FindRatio | 목표 도달 센서의 비율 | 알고리즘 안정성 평가 |
🌈 결론: 이 논문이 말해주는 것
이 논문을 읽으면서 가장 인상 깊은 부분은 **”복잡한 문제를 두 가지 간단한 방법으로 풀었다”**는 거예요:
1️⃣ 이동 단계: 단순함의 힘
- 가장 기본적인 신경망(MLP)으로도 충분
- 상수 시간의 초고속 처리 가능
- 95~100% 효율성 달성
2️⃣ 배치 단계: 목표의 균형
- 세 가지 목표(커버리지, 중복, 경계)를 동시에 달성
- K-Means 같은 기존 방법과 경쟁력 있는 성능
- 동적 환경에 대응 가능
3️⃣ 실무적 가치: 현실에 적용 가능
- 수질 모니터링: 강의 오염도 실시간 감시
- 생태계 보호: 수생 생물의 변화 추적
- 해양 안보: 항구와 선로의 감시
- 스마트 시티: 도시 하천의 통합 관리
📚 더 알아보기
이 논문의 다양한 영역을 깊이 있게 이해하려면:
- 신경망 기초: MLP와 활성화 함수의 원리
- 강화학습: PPO 알고리즘의 상세 동작
- 센서 네트워크: WSN(무선 센서 네트워크)의 설계
- 최적화: 다중 목표 최적화 문제의 해결
각각의 주제는 흥미로운 분야들이니까, 궁금하신 부분을 더 깊게 파고들어보세요!
이 논문은 🌊 수로 모니터링이라는 구체적 문제에서 출발해서 💡 일반화된 기계학습 기법을 적용한 정말 훌륭한 예시를 보여줍니다. 특히 단순한 기술로 실무적 효과를 거두는 접근 방식이 정말 인상적이네요!
여러분의 프로젝트에서도 이런 식의 두 단계 접근법이나 통합된 보상 함수 설계를 참고할 수 있을 것 같아요. 감시, 모니터링, 리소스 배치 등 유사한 문제를 다루신다면 특히 더요! 😊